Автор: Денис Аветисян
Новое исследование показывает, что умеренная эксцентриситет орбиты в двойных нейтронных звездах значительно усиливает сигналы гравитационных волн, открывая возможности для более точного изучения свойств плотной ядерной материи.
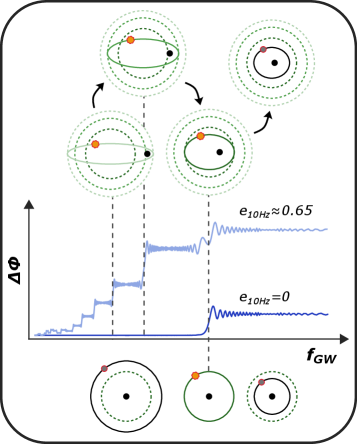
Учет эксцентриситета орбиты позволяет увеличить вероятность обнаружения низкочастотных приливных деформаций нейтронных звезд текущими гравитационно-волновыми детекторами.
Несмотря на значительный прогресс в гравитационно-волновой астрономии, выделение слабых приливных деформаций нейтронных звезд остается сложной задачей. В работе, озаглавленной ‘Orbital eccentricity can make neutron star g-mode resonances observable with current gravitational-wave detectors’, показано, что умеренные эксцентриситеты на орбите двойных нейтронных звезд могут значительно усилить наблюдаемость g-мод, слабо связанных с внешними приливными полями. Это достигается за счет увеличения фазовых сдвигов в ранней фазе эволюции системы и возникновения эпициклических резонансов, что, в свою очередь, увеличивает вероятность регистрации сигнала современными детекторами гравитационных волн более чем на порядок. Сможем ли мы, используя данные о двойных системах с эксцентриситетами e_\mathrm{10Hz}\sim0.2-0.4, получить более точные ограничения на уравнение состояния сверхплотной ядерной материи и расширить наше понимание внутренних процессов в нейтронных звездах?
Отголоски Чёрной Дыры: Новая Парадигма в Генерации Кода
Исторически сложившиеся методы генерации кода часто сталкиваются с серьезными трудностями при работе со сложными проектами и масштабированием. Традиционный подход, требующий написания каждой строки кода вручную или с использованием жестких шаблонов, становится непомерно трудоемким и ресурсозатратным по мере увеличения объема и сложности программного обеспечения. Разработка крупных систем требует огромных усилий, а внесение изменений или адаптация к новым требованиям может занимать недели или месяцы, что существенно замедляет процесс инноваций и ограничивает возможности быстрого прототипирования. В результате, компании и разработчики постоянно ищут способы автоматизировать и упростить этот процесс, стремясь к повышению производительности и снижению затрат на разработку.
В последние годы наблюдается значительный прогресс в области автоматической генерации кода благодаря использованию больших языковых моделей (LLM). Эти модели, изначально разработанные для обработки и генерации естественного языка, продемонстрировали удивительную способность понимать структуру и логику программного кода. В отличие от традиционных методов, требующих детального ручного программирования или сложных шаблонов, LLM используют принципы обработки естественного языка для анализа и создания кода на основе текстовых описаний или примеров. Этот подход позволяет существенно упростить процесс разработки, автоматизировать рутинные задачи и даже создавать код, который ранее требовал участия опытных программистов. Способность LLM к обобщению и адаптации к различным языкам программирования и стилям кодирования открывает новые возможности для повышения производительности и инноваций в сфере разработки программного обеспечения.
Эффективность больших языковых моделей (LLM) напрямую связана с их размером, что обуславливает тенденцию к созданию все более масштабных архитектур. Исследования показывают, что увеличение числа параметров модели — от миллиардов до сотен миллиардов и даже триллионов — приводит к существенному улучшению способности LLM понимать сложные запросы и генерировать корректный, функциональный код. Этот рост масштаба позволяет моделям усваивать более широкий спектр паттернов программирования, понимать нюансы синтаксиса различных языков и даже самостоятельно решать сложные задачи кодирования, ранее требовавшие значительных усилий со стороны разработчиков. В результате, наблюдается постоянное стремление к созданию еще более крупных моделей, несмотря на возрастающие вычислительные затраты и требования к инфраструктуре, поскольку именно размер является ключевым фактором, определяющим производительность и возможности LLM в области генерации кода.
За Гранью Ожидаемого: Оценка Возможностей LLM
Обучение без предварительного ознакомления (Zero-Shot Learning) демонстрирует способность большой языковой модели (LLM) генерировать программный код для задач, для которых модель не получала никаких обучающих примеров. Это означает, что LLM может использовать свои общие знания, полученные в процессе обучения на обширном корпусе текста и кода, для решения новых задач кодирования, не требуя дополнительной настройки или тонкой настройки на конкретный набор данных. Способность к Zero-Shot Learning является показателем способности модели к обобщению и пониманию логики программирования, а также к применению этих знаний в новых контекстах.
Оценка производительности в условиях обучения с небольшим количеством примеров (Few-Shot Learning) заключается в предоставлении языковой модели (LLM) ограниченного набора примеров, демонстрирующих желаемое поведение или решение задачи. Этот подход позволяет оценить способность LLM к быстрой адаптации и обобщению знаний на основе небольшого объема данных, выявляя потенциал к решению новых задач без необходимости обширного переобучения. Эффективность Few-Shot Learning измеряется по точности и скорости, с которой модель осваивает новую задачу, используя предоставленные примеры в качестве ориентира для генерации корректного кода или выполнения требуемой функции.
Оценка возможностей больших языковых моделей (LLM) в парадигмах обучения без примеров (zero-shot) и с небольшим количеством примеров (few-shot) имеет решающее значение для определения их обобщающей способности и потенциала решения новых задач кодирования. Эти подходы позволяют оценить, насколько эффективно модель может применять полученные знания к невидимым ранее сценариям, не требуя обширной переподготовки. Способность к обобщению напрямую связана с практической применимостью LLM в реальных условиях разработки, где часто возникают уникальные и непредсказуемые запросы. Использование этих парадигм позволяет количественно оценить адаптивность модели и выявить ее сильные и слабые стороны при работе с ранее неизвестным кодом и задачами.
Понимание и Создание: Рождение Интеллекта в Коде
Понимание кода позволяет большим языковым моделям (LLM) анализировать и интерпретировать существующие кодовые базы, что делает возможным выполнение задач, таких как обнаружение ошибок и автоматическое дополнение кода. Этот процесс включает в себя синтаксический и семантический анализ исходного кода, позволяя модели выявлять закономерности, зависимости и потенциальные уязвимости. Способность к пониманию кода не ограничивается конкретным языком программирования; современные LLM способны работать с различными языками, включая Python, Java, C++ и JavaScript. Эффективность обнаружения ошибок зависит от объема и качества данных, на которых обучалась модель, а также от сложности анализируемого кода. Автодополнение кода осуществляется путем предсказания наиболее вероятного продолжения текущей строки кода на основе контекста и существующих шаблонов.
Генерация кода, основываясь на понимании существующего кода, представляет собой автоматическое создание функционального программного кода на основе запросов, сформулированных на естественном языке. Этот процесс позволяет разработчикам описывать желаемую функциональность текстовым образом, после чего система генерирует соответствующий код на выбранном языке программирования. В отличие от простого копирования и вставки фрагментов, генерация кода подразумевает синтез новых конструкций и адаптацию к контексту проекта, что значительно повышает производительность разработки и снижает вероятность ошибок, связанных с ручным кодированием. Современные системы генерации кода используют различные методы, включая нейронные сети и шаблоны, для обеспечения корректности и эффективности сгенерированного кода.
Синтез программ представляет собой продвинутую форму генерации кода, ориентированную на создание полноценных и корректных программ на основе формальных спецификаций. В отличие от генерации кода из естественного языка, синтез программ требует точного и недвусмысленного описания желаемого поведения программы, выраженного в виде формальных требований, таких как логические предикаты или спецификации на основе типов. Этот процесс часто включает в себя поиск в пространстве возможных программ, используя алгоритмы поиска и методы верификации, чтобы гарантировать соответствие сгенерированного кода заданным спецификациям и отсутствие ошибок. В результате, синтез программ направлен на автоматическое создание надежного и функционального программного обеспечения, удовлетворяющего строгим требованиям.
Качество и Контроль: Оценка Кода, Созданного LLM
Функциональная корректность является основополагающим критерием оценки сгенерированного кода, поскольку именно она определяет, способен ли код выполнять поставленную задачу и выдавать ожидаемый результат. В отличие от синтаксической правильности, которая лишь гарантирует соответствие грамматическим правилам языка программирования, функциональная корректность подразумевает фактическое достижение цели, ради которой код был создан. Оценка функциональности требует проведения всестороннего тестирования с использованием различных входных данных и граничных условий, чтобы убедиться в надежности и предсказуемости поведения программы. Несмотря на развитие автоматизированных инструментов проверки, подтверждение функциональной корректности часто требует участия человека, способного оценить соответствие кода требованиям и выявить неочевидные ошибки или неэффективности.
Синтаксическая корректность является фундаментальным требованием к любому программному коду, поскольку она гарантирует, что написанный текст соответствует грамматическим правилам используемого языка программирования. Отсутствие синтаксических ошибок позволяет компилятору или интерпретатору успешно обработать код и перейти к его выполнению. Проверка синтаксиса обычно выполняется на первом этапе разработки, используя специализированные инструменты, такие как линтеры и статические анализаторы кода. Несмотря на кажущуюся простоту, обеспечение синтаксической корректности является критически важным, так как даже незначительная опечатка или неправильно поставленная скобка может привести к полной неработоспособности программы и потребовать значительных усилий для отладки.
Для автоматической оценки успешности генерации кода широко применяются количественные метрики, такие как Pass@K, позволяющие быстро проверить, насколько часто сгенерированный код проходит тесты при нескольких попытках. Однако, несмотря на эффективность автоматизированных систем, оценка нюансов качества, включая читаемость, понятность и соответствие стандартам кодирования, требует участия человека. Человеческая оценка позволяет выявить проблемы, которые не могут быть обнаружены алгоритмами, и обеспечить высокое качество программного обеспечения, особенно в контексте сложных и критически важных приложений. Таким образом, сочетание автоматизированных метрик и экспертной оценки представляет собой оптимальный подход к обеспечению надежности и удобства использования сгенерированного кода.
За горизонтом: Будущее LLM и Автоматизации Кода
Инженерия запросов, или умение правильно формулировать инструкции для больших языковых моделей (LLM), становится ключевым навыком в современной разработке программного обеспечения. Эффективный запрос позволяет разработчику точно направить LLM к генерации необходимого кода, избегая двусмысленности и нежелательных результатов. Этот процесс требует не только понимания синтаксиса и логики программирования, но и способности выражать задачу четко и лаконично, используя специфические ключевые слова и контекст. Успешная инженерия запросов значительно повышает производительность, снижает вероятность ошибок и открывает возможности для автоматизации рутинных задач, позволяя разработчикам сосредоточиться на более сложных аспектах проекта. В конечном итоге, от качества запроса напрямую зависит качество генерируемого кода и эффективность работы с LLM.
Сочетание больших языковых моделей (LLM) с надежными метриками оценки и человеческим контролем открывает принципиально новые возможности для автоматизации разработки программного обеспечения. Вместо полной замены программистов, LLM выступают как мощные инструменты, способные генерировать код, предлагать решения и автоматизировать рутинные задачи. Однако, для обеспечения качества и надежности сгенерированного кода, необходима строгая проверка, осуществляемая как автоматизированными метриками, оценивающими производительность и соответствие стандартам, так и опытными разработчиками, осуществляющими финальный контроль и внесение необходимых корректировок. Такой симбиоз позволяет значительно ускорить процесс разработки, снизить вероятность ошибок и высвободить ресурсы для решения более сложных и творческих задач, что, в конечном итоге, способствует инновациям и повышению эффективности в различных отраслях.
Постоянное развитие генерации кода на основе больших языковых моделей (LLM) сулит значительные изменения в сфере разработки программного обеспечения, открывая возможности для демократизации процесса создания приложений. Ранее требующие глубоких знаний в области программирования, задачи теперь становятся доступнее для более широкого круга специалистов и даже людей без специального образования. Автоматизация рутинных операций, таких как написание шаблонного кода и тестирование, позволяет разработчикам сосредоточиться на решении более сложных и творческих задач, что, в свою очередь, ускоряет инновации в различных отраслях — от финансов и медицины до образования и развлечений. Ожидается, что этот процесс приведет к появлению новых инструментов и платформ, позволяющих создавать программное обеспечение быстрее, эффективнее и с меньшими затратами, способствуя тем самым технологическому прогрессу и расширению возможностей для бизнеса и потребителей.
Исследование, представленное в данной работе, демонстрирует, как умеренная эксцентричность орбиты может значительно усилить возможность обнаружения низкочастотных приливных деформаций нейтронных звезд. Это открывает путь к более точным ограничениям уравнения состояния плотной ядерной материи посредством наблюдений гравитационных волн. В этом контексте вспоминается высказывание Исаака Ньютона: «Я не знаю, как меня воспринимают другие, но мне кажется, что я был всего лишь ребенком, играющим с гальками на берегу моря, и находящим более гладкие, чем другие, пока огромный океан истины оставался неисследованным». Подобно тому, как Ньютон исследовал мир, данное исследование, стремясь обнаружить слабые сигналы гравитационных волн, напоминает о границах нашего познания и о том, что даже самые точные теории могут потребовать пересмотра перед лицом новых данных.
Что же дальше?
Представленная работа, демонстрируя влияние умеренной эксцентричности на наблюдаемость g-мод нейтронных звёзд, открывает новую главу в поиске пределов нашего понимания. Однако, стоит признать, что даже усиление сигнала не гарантирует полного раскрытия тайн плотной ядерной материи. Уравнение состояния, оставаясь неуловимым, продолжает напоминать о границах применимости существующих моделей. Космос щедро показывает свои тайны тем, кто готов смириться с тем, что не всё объяснимо.
Дальнейшие исследования, вероятно, будут сосредоточены на более реалистичных моделях бинарных систем нейтронных звёзд, учитывающих сложные эффекты, такие как аккреция и взаимодействие с магнитными полями. Необходимо также уделить внимание разработке более совершенных алгоритмов анализа данных, способных извлекать слабые сигналы из шума. Чёрные дыры — это природные комментарии к нашей гордыне, и поиск g-мод — лишь ещё одна попытка услышать отголоски этого комментария.
В конечном счёте, успех в этой области зависит не только от технологического прогресса, но и от готовности признать, что любое уравнение, любая модель — лишь приближение к истине. И горизонт событий, как ни крути, всегда маячит где-то неподалёку.
Оригинал статьи: https://arxiv.org/pdf/2602.15111.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Саламандра в радиоволнах: Раскрытие тайн сверхновой G309.8-2.6
- Поиск Эха Вселенной: Совместное Наблюдение Гравитационных Волн и Нейтрино
- Радиоизлучение галактик: новый взгляд на связь со звёздообразованием
- Тёмная энергия: новые данные и старые противоречия
- Космологические парадоксы и судьба Вселенной: взгляд на модель «Большого Разрыва»
- Охота за тёмной материей: Радиоастрономический поиск аксионов
- Взрывные сигналы из глубин Вселенной: классификация гамма-всплесков с помощью машинного обучения
- Загадочные Красные Точки: Новое Видение Ранней Вселенной
- Широкие двойные звезды: танец гравитации и массы
- Чёрные дыры и галактики: новая картина эволюции
2026-02-19 04:04